DevOpando em ambientes Windows com Performance Counters - Requests per Second
Comments
30 November 2012
Quando desenvolvimentos aplicaçoes, conhecer bem o ambiente em que fazemos o deploy é fundamental. Principalmente quando falamos de aplicaçoes web e abertas pra internet. Estas aplicaçoes estao mais expostas e sujeitas a todo tipo de situaçoes como um pico de acessos e até maldosos ataques. Geralmente esta tarefa é deixada para a equipe de infra-estrutura, mas cada vez mais os desenvolvedores estao se metendo nessa área e aprendendo a configurar e otimizar seus servidores.
Vamos DevOpar!
Performance Counters
Este é um assunto que gosto muito e que vou explorar agora começando com performance counters. Performance counters, como o próprio nome diz, sao contadores que o Windows e muitas aplicaçoes que rodam sobre ele disponibilizam pra nós. Por meio destes contadores é possível verificar desde o uso de CPU da máquina até informaçoes detalhadas sobre a execuçao do Garbage Collector em aplicaçoes .NET.
Performance Monitor
Para ter acesso aos contadores de performance basta digitar "perfmon" no prompt "Executar" do Windows:
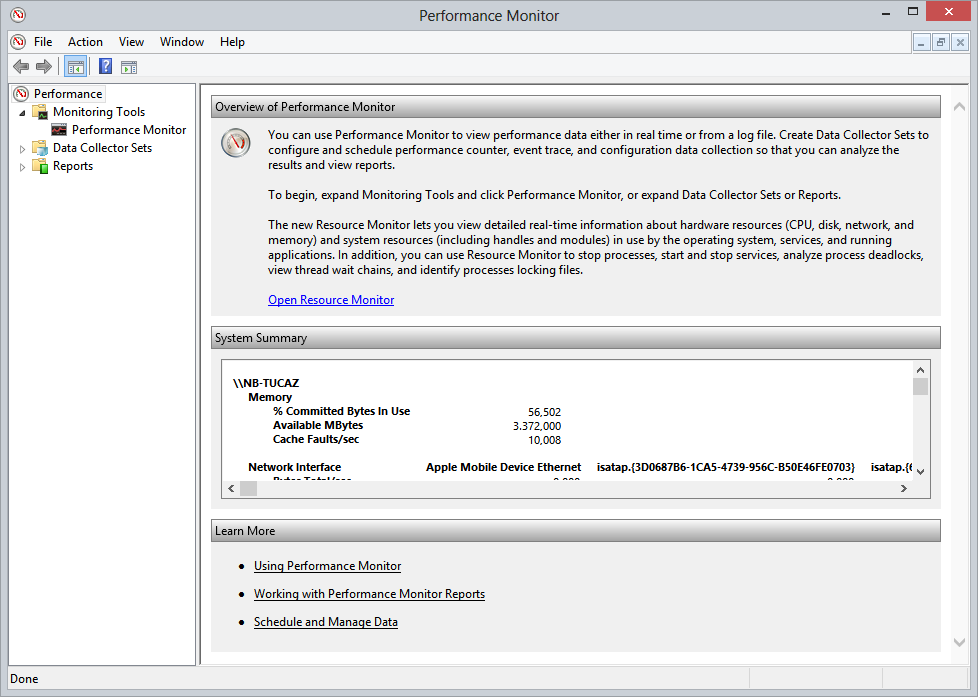
que a janela principal do Perfomance Monitor se abrirá já com algumas informaçoes básicas sobre sua máquina:
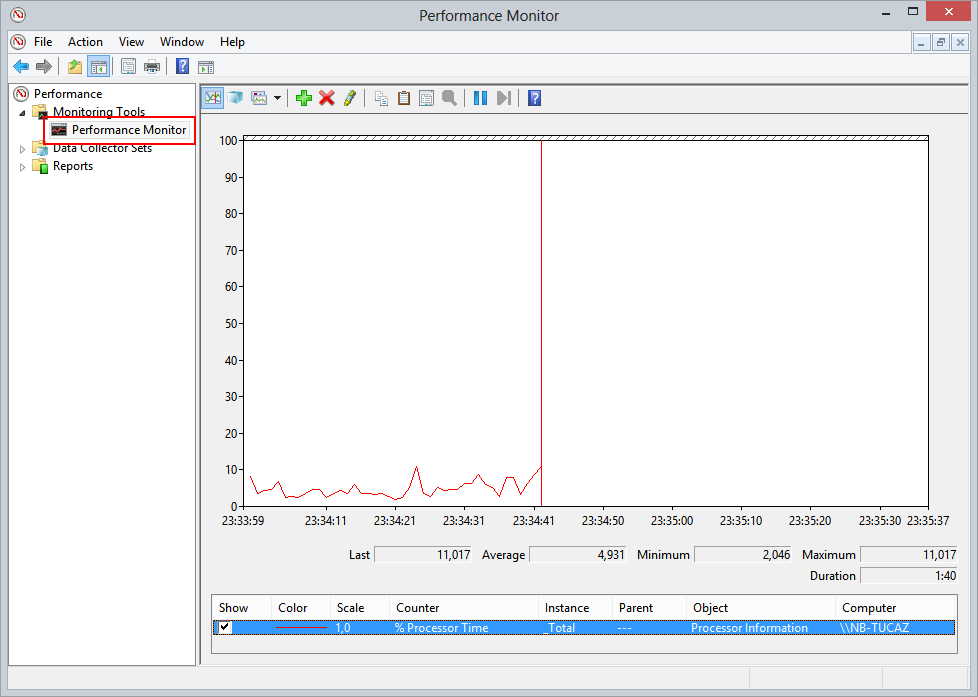
Clicando em "Performance Monitor" ganhamos acesso a o que realmente nos interessa:
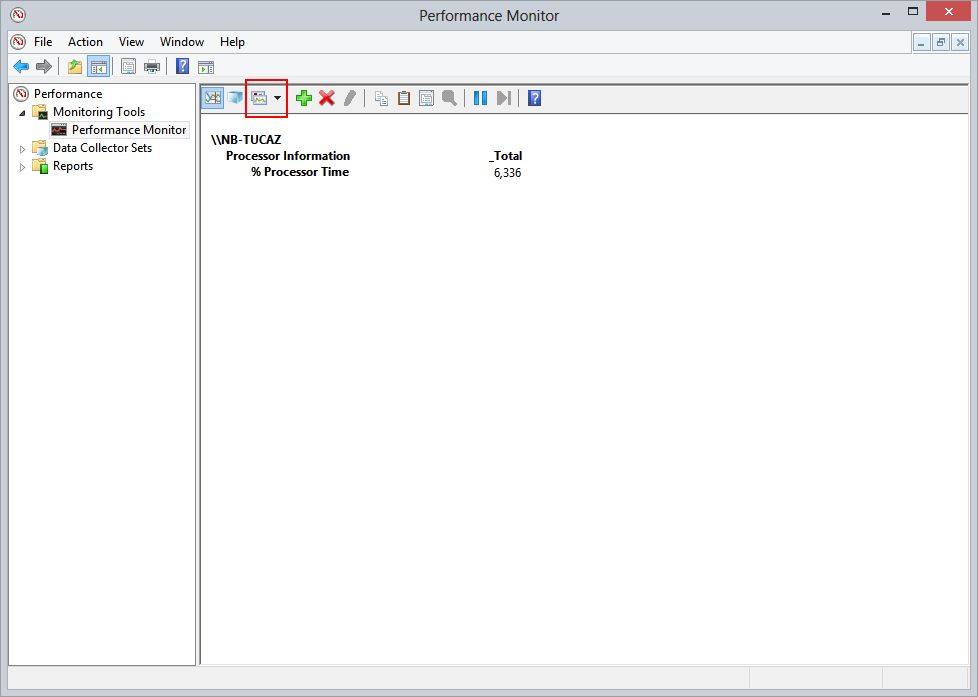
Através do botao existente na barra de tarefas é possível trocar o tipo do gráfico e mudar para um que nôs de os valores absolutos dos contadores que já traz, por padrao, a utilizaçao de CPU:
Requests Per Second / Requisiçoes Por Segundo
Agora que já nos ambientamos com nossa nova ferramenta de trabalho vamos começar a falar dos contadores em si. O primeiro que vou falar a respeito é Requests Per Second, ou na sigla, RPS.
Este contador é o mais básico e ainda um dos mais importante quando analisamos qualquer aspecto relacionado a performance em aplicaçoes Web. Ele nos fornece o número de requisiçoes que uma instância do .NET (comumente um site do IIS) está executando a cada segundo.
Baseado no número de requests podemos dizer se nossa aplicaçao irá ou nao aguentar a demanda prevista ou identificar o momento (número de requests) em que nossa aplicaçao começa a se comportar mal, por exemplo [1]. A partir deste contador é que a análise de todos os outros fará sentido.
Para incluí-lo na sua janela do performance monitor basta utilizar o botao "Adicionar" na barra de ferramentas.
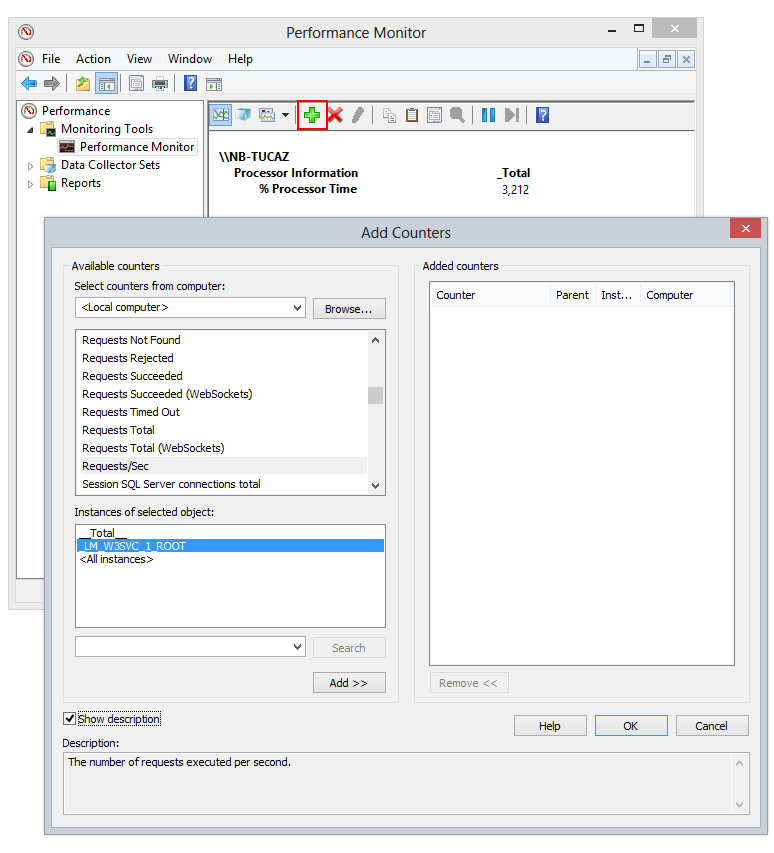
É importante entender que todo contador está sempre associado a uma instância que será selecionada no momento que adicionamos o contador. Neste caso, uma instância é um site do IIS, mas em outros casos podemos encontrar o acumulado de todas as instâncias disponível em uma instância chamada _Global_ ou _Total_, um executável .NET ou até mesmo uma instância especifíca de um serviço exposto por meio de WCF.
Este contador está localizado dentro do grupo ASP.NET Applications com o nome de Requests/Sec [2].
Uma vez adicionado, você verá, em tempo real [3], o número de requisiçoes por segundo que seu site está atendendo. Na maioria das aplicaçoes este número é relativamente baixo nao passando de 5 ou 10 já que pra que este contador seja incrementado é necessário que as requests sejam executadas exatamente no mesmo segundo. Isto geralmente acontece em duas situaçoes: você tem vários usuários acessando sua aplicaçao ao mesmo tempo ou caso suas requisiçoes demorem muito pra terminar a execuçao.
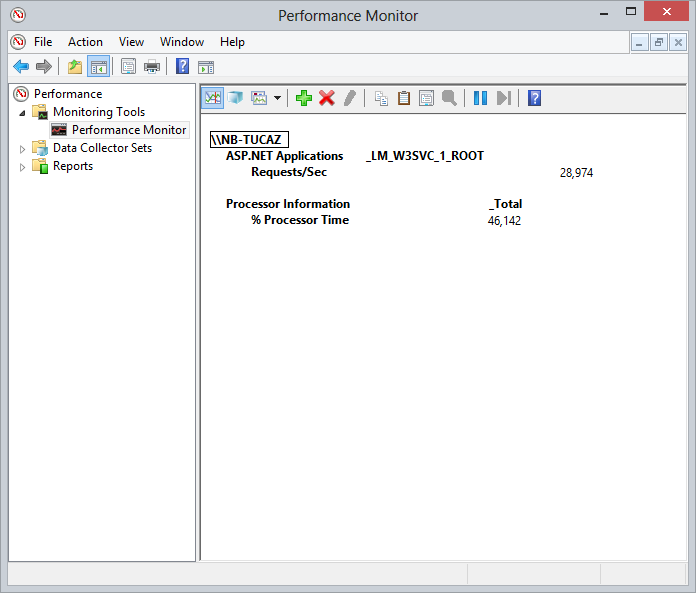
Já em alguma aplicaçoes este número pode ser bem alto. O Tumblr por exemplo, atende cerca de 40 mil [4] requisiçoes em um dado segundo o que requer uma arquitetura bem desenhada e implementada.
Nos próximos posts sobre este assunto vou falar de contadores de exceptions, caching, memória e diversos outros que devem ser monitorados e medidos pra garantir a boa saúde de sua aplicaçao.
Era isso. :)
[1] Ele também serve pra você se gabar para seus amigos nerds já que construir uma aplicaçao que atende milhares de RPS nao é trivial
[2] A Microsoft pisou na bola na hora de nomear os contadores do Windows na versao em Português. O nome dos contadores foi traduzido. A maioria deles você consegue encontrar facilmente, mas alguns tem nomes totalmente toscos e por conta da ordenaçao alfabética contadores relacionados acabam ficando em posiçoes nao sequencias dentro de seus grupos o que é um pé no saco.
[3] Os contadores sao coletados em intervalos super baixos (1 em 1 segundo no Windows 8 Ultimate, por exemplo) o que, pra todos os efeitos, é em tempo real e este valor é configuável por meio das propriedades do Performance Monitor.
[4] Fonte - http://highscalability.com/blog/2012/2/13/tumblr-architecture-15-billion-page-views-a-month-and-harder.html
